ByteMLPerf Micro Perf 概览
框架
ByteMLPerf Micro Perf Vendor 架构如下图所示:
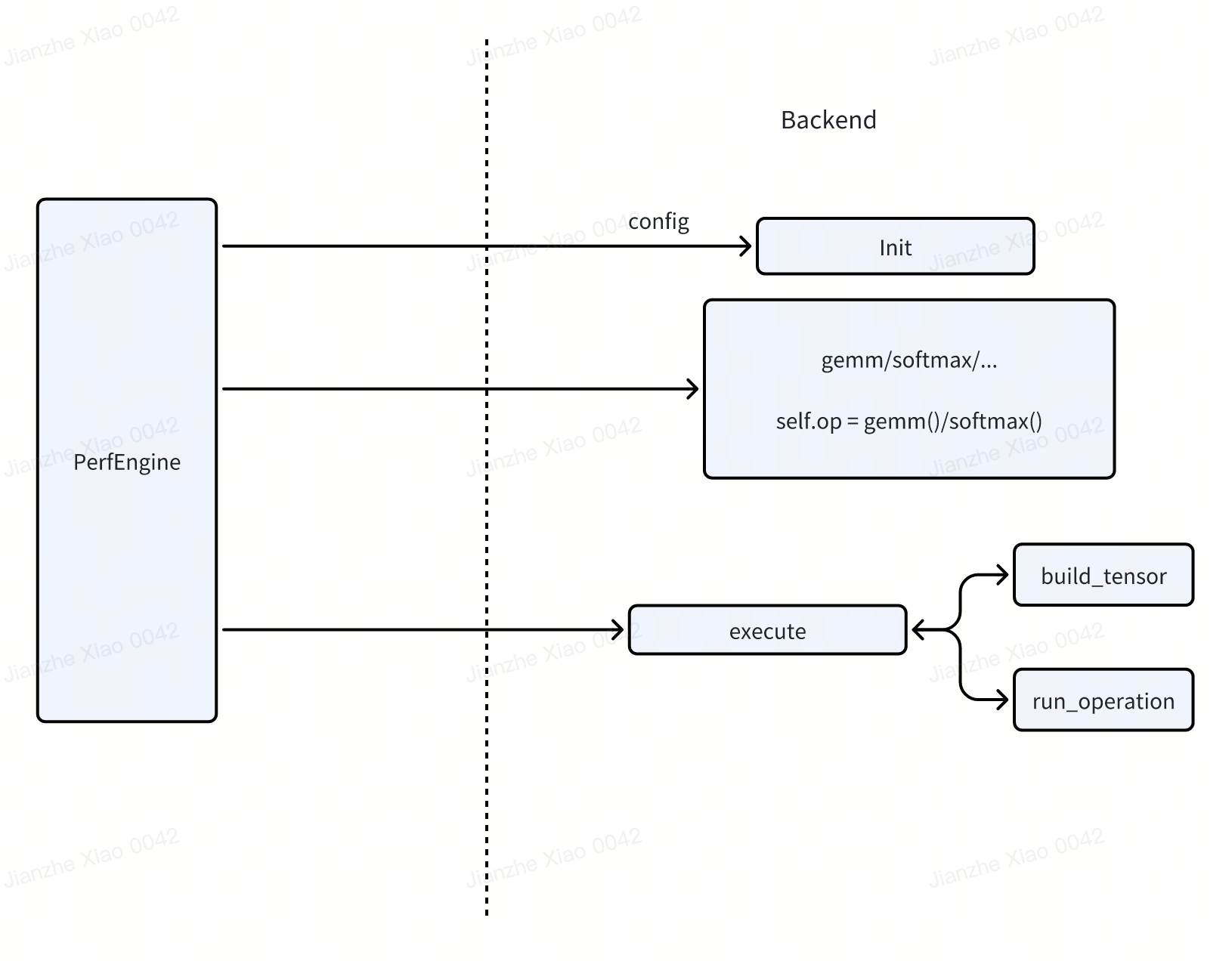
User Interface
用户使用入口为launch.py, 在使用 byte mlperf 评估时,只需传入--task 、--hardware_type 两个参数,如下所示:
- task
--task 参数为待评测算子的 workload 名字,无默认值,必须用户指定。例如:若要评估 Add 算子的 workload,则需指定--task add。
注:所有 workload 定义在 byte_microperf/workloads 下,传参时名字需要和文件名对齐。目前格式为 kernel_name.
- hardware_type
--hardware_type 参数为传入的 hardware_type 名字,无默认值,必须用户指定。例如:若要评估 GPU,则需指定--hardware_type GPU。
注:所有 hardware type 定义在 byte_microperf/backends 下,传参时名字需要和 folder 名对齐。
- vendor_path
--vendor_path 参数为传入的新硬件配置文件路径,无默认值,必须用户指定。例如:若要评估 GPU,则需指定--hardware_type ../vendor_zoo/NVIDIA/A100-PCIe.json。
注:若未提供指定格式的配置文件,则需要在 backends/backend_xpu.py 内传入硬件相关的参数。
评估类别
四类评估:GEMM、Vector、通信、Kernel Launch。
GEMM
引入目的: 评估新硬件的峰值算子,以及按如下配置评估该算子在不同输入形状的条件能达到多高的峰值计算能力。 关键配置 [M, K, N],这里又可以分为 8 类,如下图:
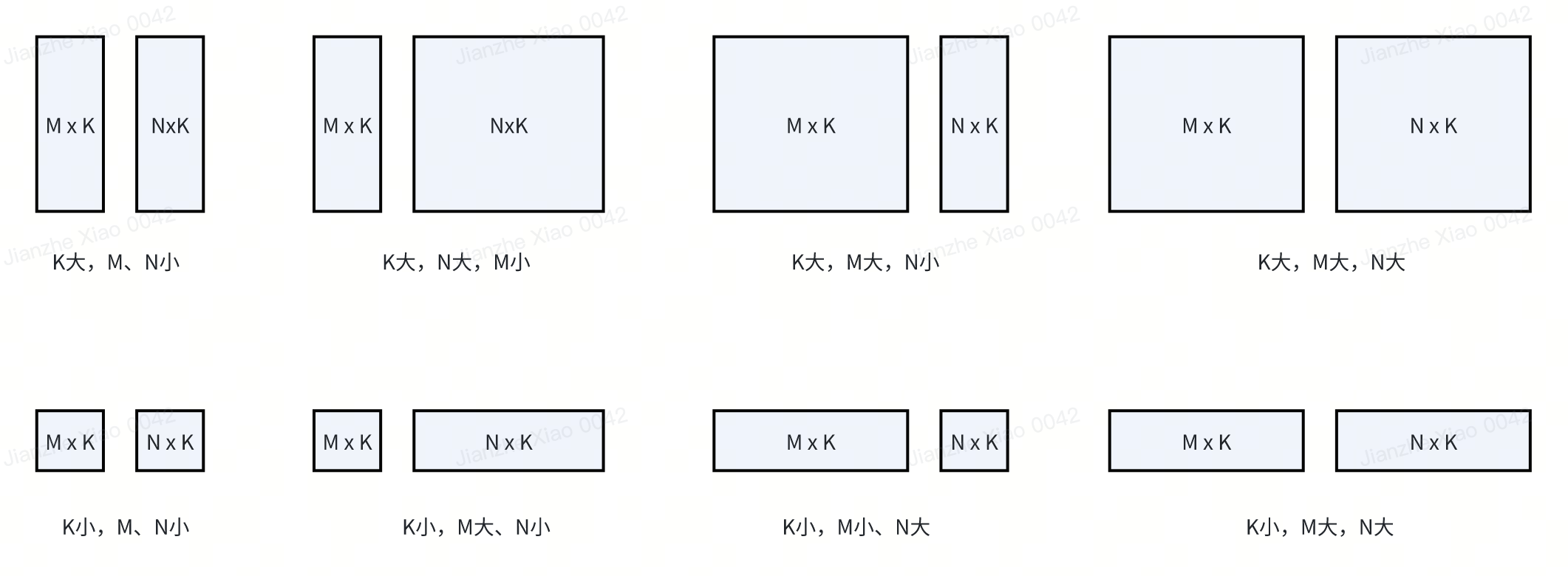
按照极小、均衡、极大选取三个数字。全部评测集为 M K N 组合排列, M:[64, 2048, 65536] K:[64, 2048, 65536] N:[64, 2048, 65536] [M, K] x [K, N] -> [M, N]: 2MNK 次浮点运算
Vector
Add
引入目的: 如果操作数在 global memory 上,element-wise 的操作,基本上是在评估 global memory 的读带宽,因为需要的计算少,IO 多。
Softmax
引入目的: softmax 可以稍微均衡的评估 vector 算力,该算子会在不同的输入 shape 下受限于 IO 或计算。
IndexAdd
公式:
引入目的: Index 相关的操作预估在新硬件上特别耗时
Special Function
- Exp/Sin/Cos: 评估新硬件在特殊函数上的性能,是否有特殊函数单元的硬件加速。
Random Function
- Exponential_: 引入目的: 评估随机函数的生成速度,是否有硬件上的相关算法加速