AI ASIC 的基准测试、优化和生态系统协作的整合
日期: 2023-12-02
9月26-28日,由Linux 基金会、CNCF 主办的KubeCon + CloudNativeCon + Open Source Summit China 2023 在上海举办。作为社区积极贡献者和最终用户,字节跳动和火山引擎团队在此次大会上进行了 7 个分享—— KubeCon 2023 | 字节跳动是怎么为 AI 打造云原生基础设施的。本系列内容根据此次会议分享整理而成,欢迎关注。

ByteMlPerf 是字节开源的一套“整合 AI ASIC 的评估、优化和生态系统协作” 的解决方案。
本次分享分为 3 个部分:
-
因为 ByteMlPerf 是围绕 AI ASICs 展开的,所以第一部分会先介绍背景,即什么是 AI 专用芯片,以及为什么 AI 专用芯片现在越来越受关注;
-
第二部分会介绍我们做 ByteMlPerf 的动机,毕竟业界现在 MlPerf 名声很大,为什么还要另起炉灶,做一套 ByteMlPerf?
-
第三部分会在第二部分的基础上展开,有了做 ByteMlPerf 的动机之后,我们实际如何解决在使用 ASIC 时候遇见的问题。
背景介绍
为什么 AI ASIC 现在越来越受关注
我们先大概回顾下神经网络的发展过程。
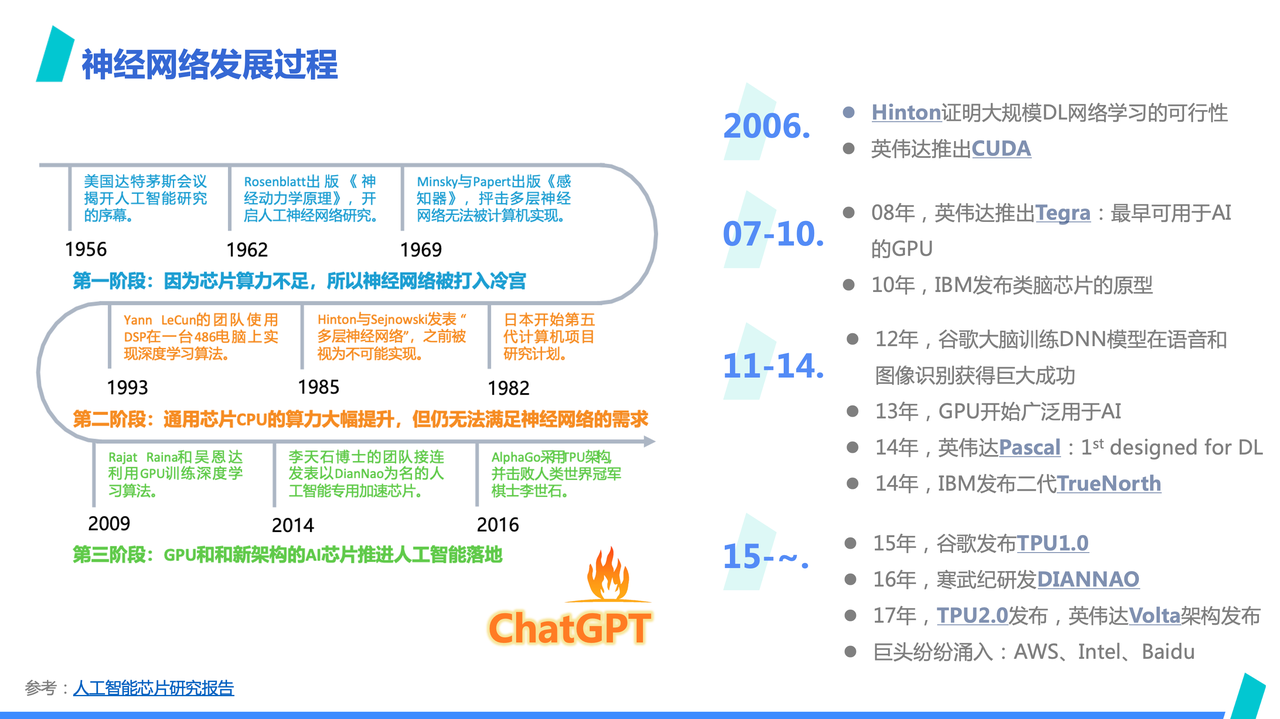
上方这张图来自人工智能芯片研究报告, 从这张图可以看到,神经网络目前为止在历史上经过三个阶段,每个阶段的发展,都和算力供应的提升有很大的关系:
-
第一阶段,由于当时 CPU 算力不足,神经网络被打入冷宫;
-
第二阶段,随着 CPU 计算能力有所提升,有些许进展但算力明显不足仍然是最明显问题,这个阶段也并没得到大的发展;
-
第三阶段,GPU 和其他新架构的 AI 芯片出现,提供了足够的算力,同时互联网世界也沉淀了足量的训练数据,神经网络开始蓬勃发展。
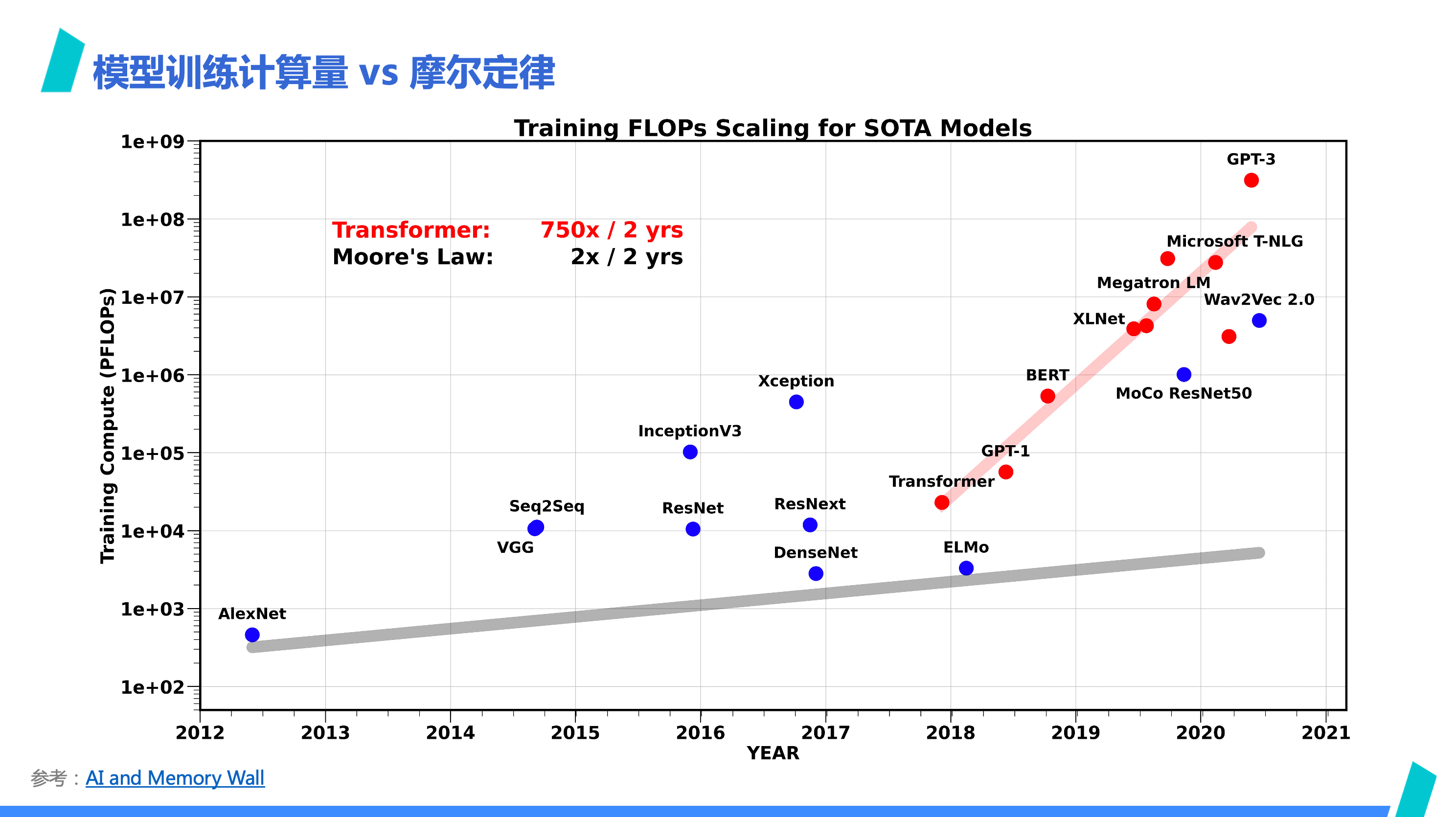
我们来看一张 「模型训练计算量和摩尔定律」的对比图,这张图来自 AI and Memory Wall。
从图里可以明显看出,摩尔定律完全跟不上 Transformer 类模型训练需要的算力,而摩尔定律某种程度上其实反应着芯片制造工艺的发展,面对红色线和灰色线如此大的差距,依赖通用算力芯片中放入更多晶体管来提高算力的途径,很难跟上模型训练的算力需求,使得我们不得不更依赖集群计算。
说到这里,大概就能回答第一部分的第一个问题:为什么 AI ASIC 现在越来越受关注——在物理世界的约束下,依赖摩尔定律的通用算力没法满足需求增长,而为了破局,专项专用计算架构成为为数不多的可选的道路。
什么是 AI 专用加速芯片
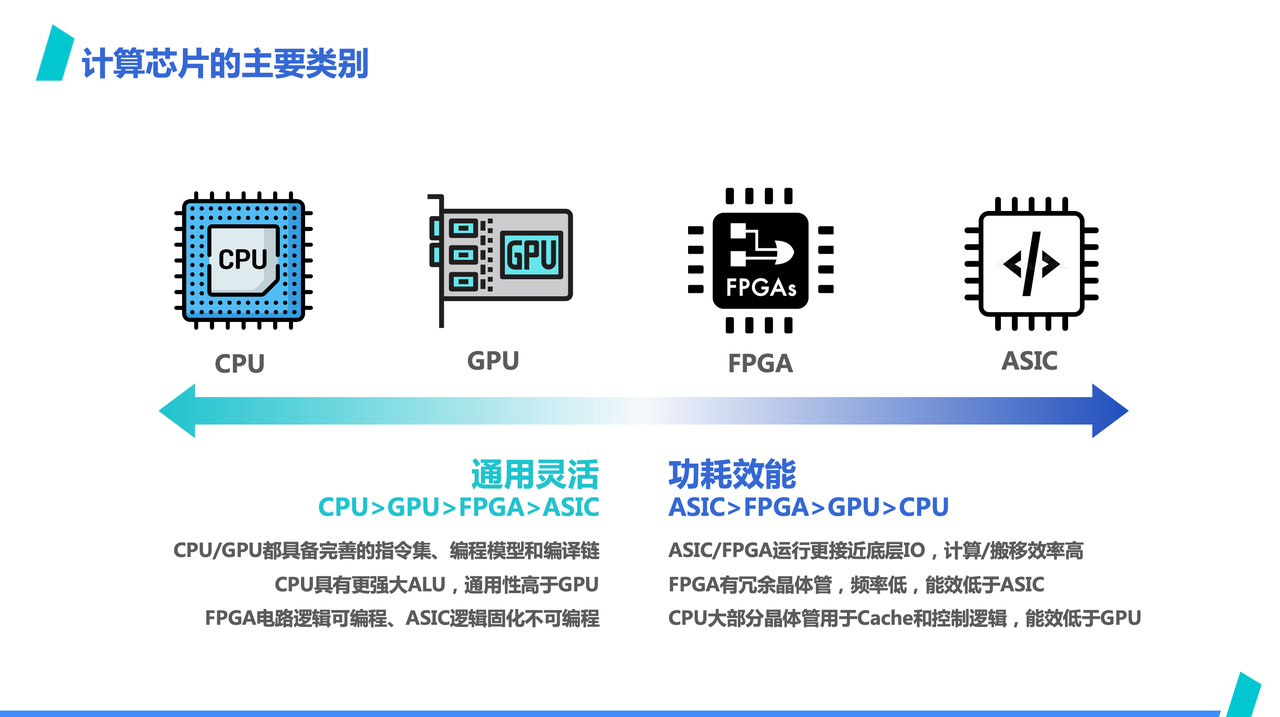
AI 专用加速芯片的概念是相对通用算力芯片来说的,像这里提到的,左边 CPU、GPU 我们通常称之为通用算力,二者可以跑的运算负载很多元,CPU 不用多说,GPU 除了可以跑 AI,还可以跑图像处理,高性能计算等负载,而 AI 专用加速芯片一般只能跑 AI 负载;
我们说 AI 专用加速芯片的时候,往往是在说右边两个分类,但由于 FPGA 实际上往往更多用来做设计验证,很少见到以 FPGA 形态做量产产品,所以我们在提到 AI 专用加速芯片的时候,更多的其实就是在说 AI ASIC。当然,严格来讲,某些具备一定灵活性的 AI NPU 架构的芯片,可能并不严格属于 ASIC,但为了方便统一,就暂时先归入 ASIC 类了,用 ASIC 代指 AI 专用加速芯片。
从这也可以看出,ASIC 最突出的是在能效比上会比通用芯片有优势。这是因为,其底层运行逻辑会更接近 IO,没有通用芯片上复杂的电路逻辑,而同样的芯片面积的情况下,ASIC 能给算力预留的芯片面积则更大,也更容易做出算力更高的产品;而相应的,AI ASIC 在通用性上,受限于架构,就不如 CPU、GPU,一般而言只能运行 AI 负载,不能用作他用,编程灵活性上相对会差不少。
我们来看一例子 —— Habana Goya 的架构。这是一款 Habana Lab 公司的 AI 推理卡,是一个很典型的 ASIC 架构,架构很简洁,也很 AI 专用。
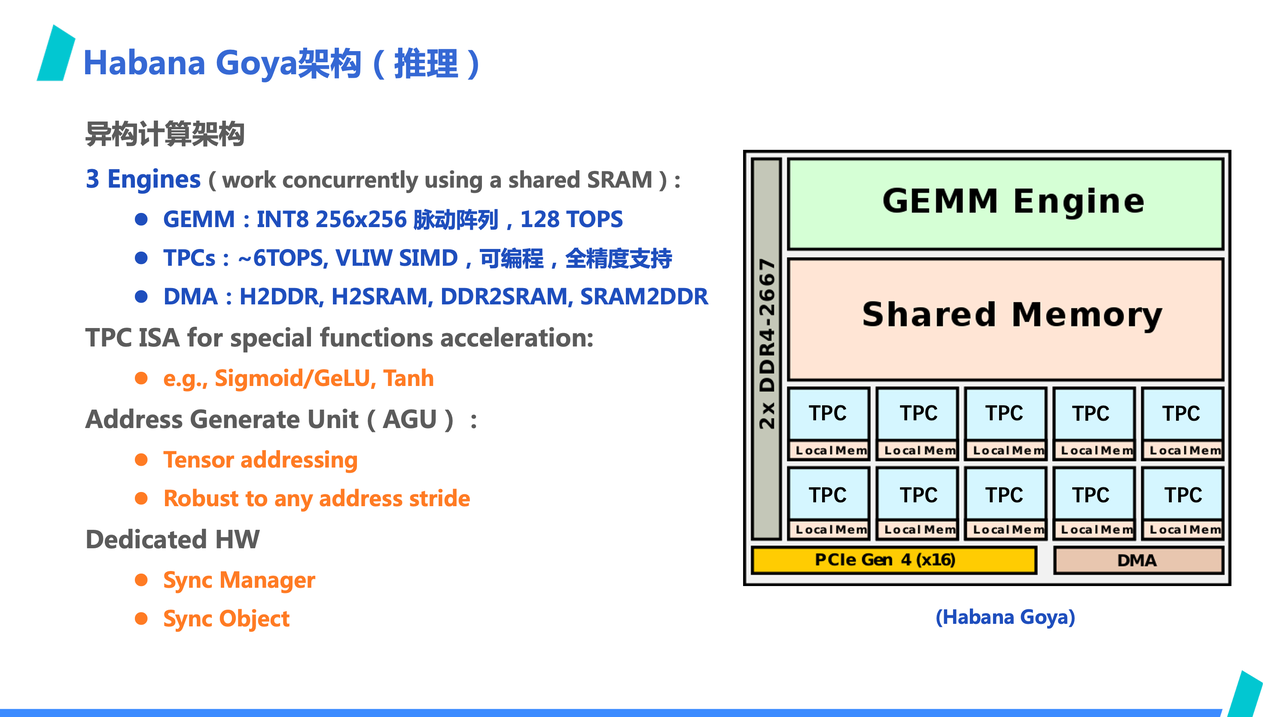
首先,从右边的架构图中,看到不到取址、译码等复杂控制逻辑,数据传递是通过共享的 SRAM,同步协同的是通过专用的 Sync Manager 硬件,这是一个类似硬件信号量的东西。算力构成方便主要是 GEMM Engine 和 8 个 TPC 构成,乘加算力主要是由 GEMM 提供,TPC 更多是充当非乘加类算力的补充,这主要是因为目前 AI 负载的主要运算是乘加运算。
为了更好契合 AI 计算,地址生成单元配合专用 DMA,可以实现 Tensor 风格访存,可将 Tensor 下标变成对应的线性地址,而且支持相应的维度越界检查。除了 -1 轴之外,其他维度支持任意 stride 访存,此外,GEMM、TPC、DMA 的指令序列是独立的,pipeline 运行时是 latency 会被隐藏起来。
此外,TPC 也添加了 AI 负载常见的激活函数,作为特殊指令来支持 AI 负载。比如直接提供了 sigmoid、gelu 等
为什么要做ByteMLPerf
回答这个问题之前,我们要先回答一个问题,AI ASIC 为什么实际落地到业务生产中的并不常见?

根据我们的经验,对于一家公司来说,虽然 AI ASIC 可以解决算力供应问题,想要使用 AI ASIC 来提供算力其实并不是一件容易的事情。
首先,产品抉择难。如何选择适合的产品本身就是一个问题。这点相信对于使用 GPU 产品的公司很难领会,但面临市场上五花八门的 AI 加速芯片,如何选择适合业务的产品本身就会是一个问题。
第二点,不可控性高。和 GPU 不一样,AI ASIC 作为新产品,是否最终可以落地业务的不可预测性显然更高。
第三点,适配成本高。ASIC 一般不具备成熟的开发者生态,使用门槛高。
第四点,不透明性高。ASIC 的不灵活及可编程性弱导致 ASIC 会很依赖于自己的编译器,而这部分对于用户来说,通常是不可见的。
产品抉择难在哪儿

先来看一张图,这张图是唐杉博士整理一张 AI 芯片全景图,图是 2019 年的,到今天已经有点过时了。但从这样图多少可以看出一些问题,面对如此繁多,花样百出的各家 start up 提出的产品,选择引入哪个产品?
这个问题的答案不仅仅是芯片纸面实力的选择,还需要考虑公司人员稳定性,融资能力,交付能力,客户支持能力,软硬件迭代周期等因素,毕竟硬件产品的生命周期比较长,需要长期投入。
不可控性体现在哪儿
首先引入硬件产品的周期比较长,往往需要跨部门协同沟通,业务、系统、供应都会参与。当通过硬件规格选定引入一个新产品后,硬件应用到的实际业务,是否可以满足预期是存在一定风险的。如果实际业务效果,无法像设计规格体现的那样具备收益,那前期适配、测试投入的成本就会变成沉没成本。
这里的不可控还不仅仅是吞吐和时延上的不可控,还有精度方面的风险,从 GPU 迁移到 ASIC 上,尽管代数计算是等价的,但实际运行一般都会出现模型输出数值漂移情况,而这种数值漂移在业务场景是否能被接受,这点也同样存在风险。
适配成本高在哪
使用 ASIC 可能出现的一个情况是,某家公司的产品可能在某个业务方向效果很好,但在另外一个业务方向上表现一般。
所以为了满足不同业务负载特点,可能会出现需要引入多家 ASIC 的情况,而各家 ASIC 由于具备类似 CUDA 的开发生态,往往都需要单独适配,且各家 ASIC 往往都会自带一套自身的软件栈,从使用方式,硬件管理,监控接入等层面,都需要额外开发。
这些相比沿用 GPU,都是额外成本。
不透明性体现在哪
关于不透明性,就像刚才 Habana 的例子提到的,ASIC 的架构乍一看会很简单,但其实很多硬件的设计细节作为核心技术,作为终端使用者都无法获得。
而在软件上,刚刚也提到,ASIC 公司一般都会给自家产品配到一套的完整的软件栈,其中就包括其编译器,和设计细节一样,编译器对于终端使用来说也是不透明的。
大多数 ASIC 都很难支持开发者像优化 CUDA Kernel 一样优化 ASIC 上运行的 AI 模型性能,往往只能做的很有限。
ByteMLPerf的方案
对比和区别
在第二部分,其实没有提到一点,就是已经有了 MLPerf,为什么还要另起炉灶,做一套 ByteMlPerf 呢?简单来说,这是因为 MLPerf 很难满足业务实际评估需求。这里可以简单做些对比:
首先,评估的视角不一样,ByteMlPerf 是纯粹从用户的角度发起的评估,而 MLPerf 是由供应商委员会主持,这就导致两边侧重点不一样;
其次,在公平性上,ByteMlperf 不会要求 apple 2 apple 的对齐,而是以效果导向,接受厂商黑科技。
接着,ByteMlPerf 的评测集更新会更快,会紧跟业务需求和 SOTA 模型,当我们发现业务大面积使用的模型发生迭代,我们也会及时更新,并通知厂商;
最后,ByteMLPerf 会按照业务使用方式,约束评估接入的方式,将使用方式抽象成 API,约定 API 的返回格式,但不约束 API 实现过程;
作为结果,MLPerf 的评估结果某种程度变成了厂商想尽办法秀肌肉的地方,但评估结果中的数字,却离实际业务应用有很长一段距离。
ByteMLPerf的特点

第一点,透明与可复现性。开源就不用说了,透明是由于我们要求厂商不仅要提供评估结果,同时要提供复现环境,以及如何在 Bytemlperf 框架约束下,得出的评估结果,这样就可以尽可能保证评估结果的可复现性,以及当实际业务中用到了类似的模型时,也可以得出类似的评估结果。
第二点,面对 AI 生产场景。这是指 ByteMLPerf 的评估流程是根据实际生产场景设计的,某成程度上,Bytemlperf 不仅仅是评估套件,它其实完全可以作为生产工具,接入到生产流程中。
第三点,紧随业务和 SOTA。为了确保与最新的技术和业务需求保持一致,ByteMLPerf 持续更新其基准测试,反映出当前业务场景的需求和前沿技术,为用户提供了最新、最相关的性能评估,也让厂商可以及时当前那些模型应用最广。

为了解决选择难的问题,BytemlPerf 收集了市面上常见的硬件产品信息,并汇总在一起,就像大家在这张图里看到的。当然,信息大盘不会包括所有市面上有的产品,因为 Bytemlperf 通过约束评估接入方式,以及报告提交门槛,会初步过滤掉一些硬件、软件还不成熟的产品。
当然,暂时不在大盘中并不代表其产品就不成熟,而是因为接触厂商、收集信息、接入评估及报告提交都需要时间,我们还需要时间进一步收集。
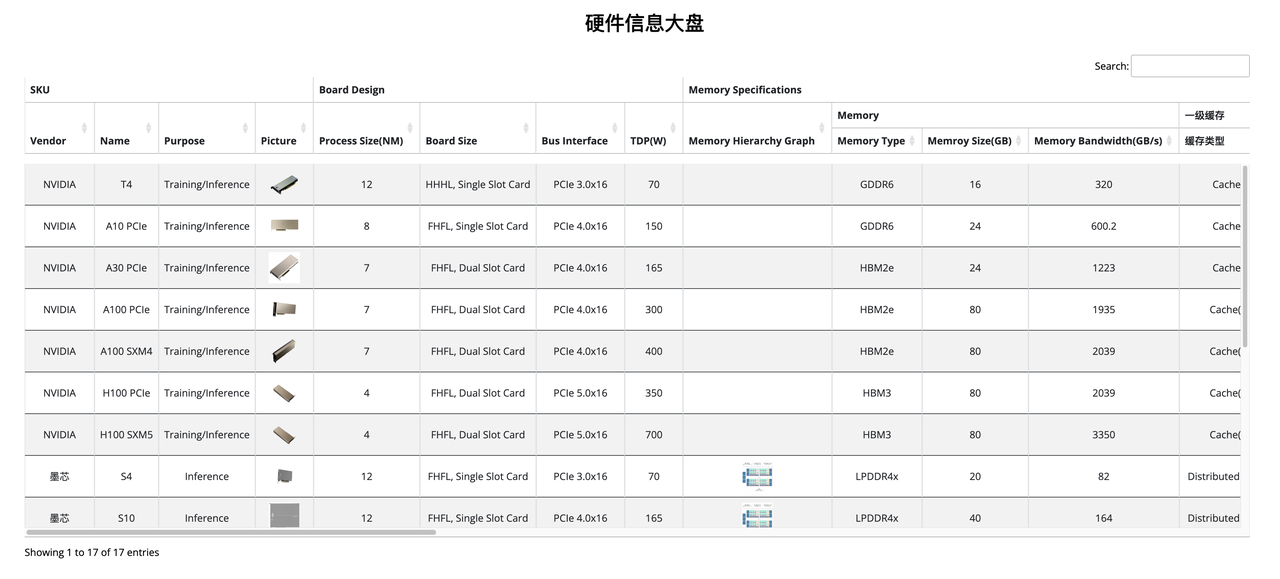
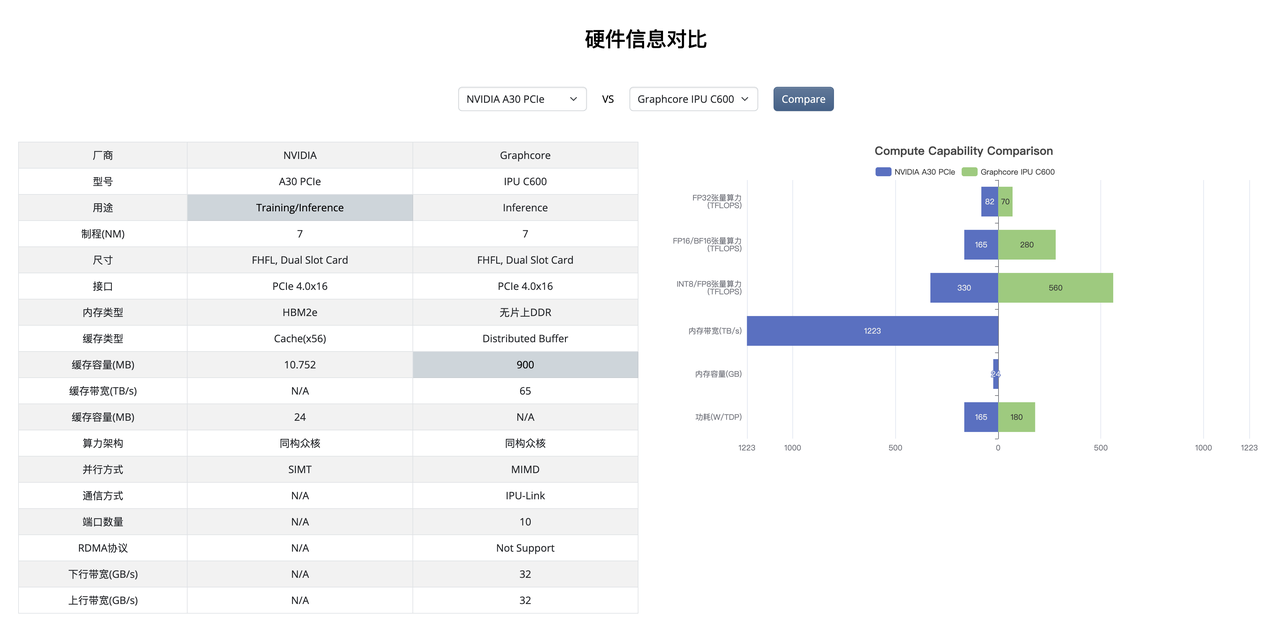
而为了解决选择难的问题,我们设计硬件信息对比的功能,如果第一步不知道如何选择,可以先从当前在使用的产品作为基准,看看有什么产品接近或者规格上更优于目前使用的产品;第二步,可以看看在该厂商已经提交的报告中,是否有当前业务在大量使用的模型,如果有,那我相信下一步自然就是和厂商进一步接触了。
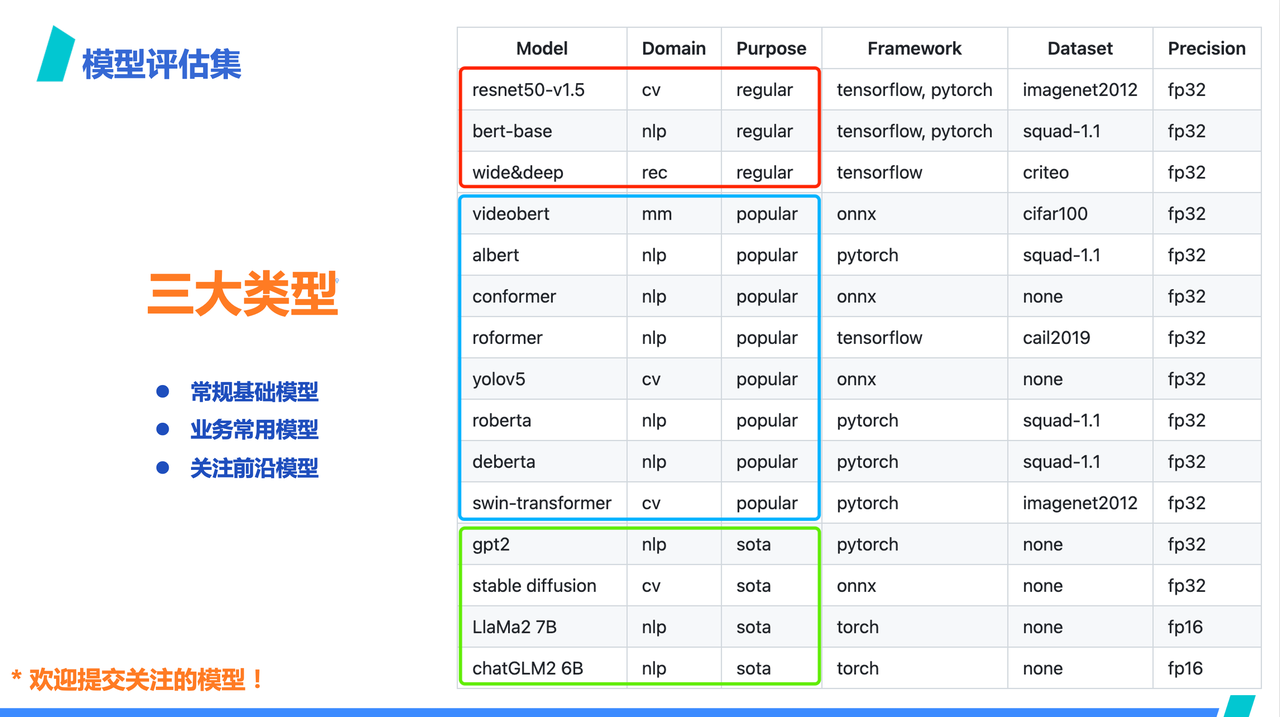
我们是希望通过全面的评测集来降低不可预测性的风险。就像之前讲到的,为了确保与最新的技术和业务需求保持一致,ByteMLPerf 持续更新其基准测试。这部分展开讲,可以简单分为三个部分:
第一部分:常规基准模型。Bytemlperf 的报告提交规范中,会要求厂商至少提交 5 个不同模型的报告,其中常规模型是都要提交的,也即,如果常规模型支持不好,那就没有不满足 Bytemlperf 的入门要求;
第二部分,业务常用模型。这是我们目前根据业务实际使用情况过滤出来的常用的模型。在这部分选择中,厂商可以选择着重表现哪个,比如语言处理类,还是图像处理类?
第三部分,是前沿模型。这是考虑到硬件产品的长期投入,现在用量不多的模型不久之后就会大规模在生产场景中使用。
当然,我们很欢迎大家往 ByteMLperf 提交自家感兴趣的模型!
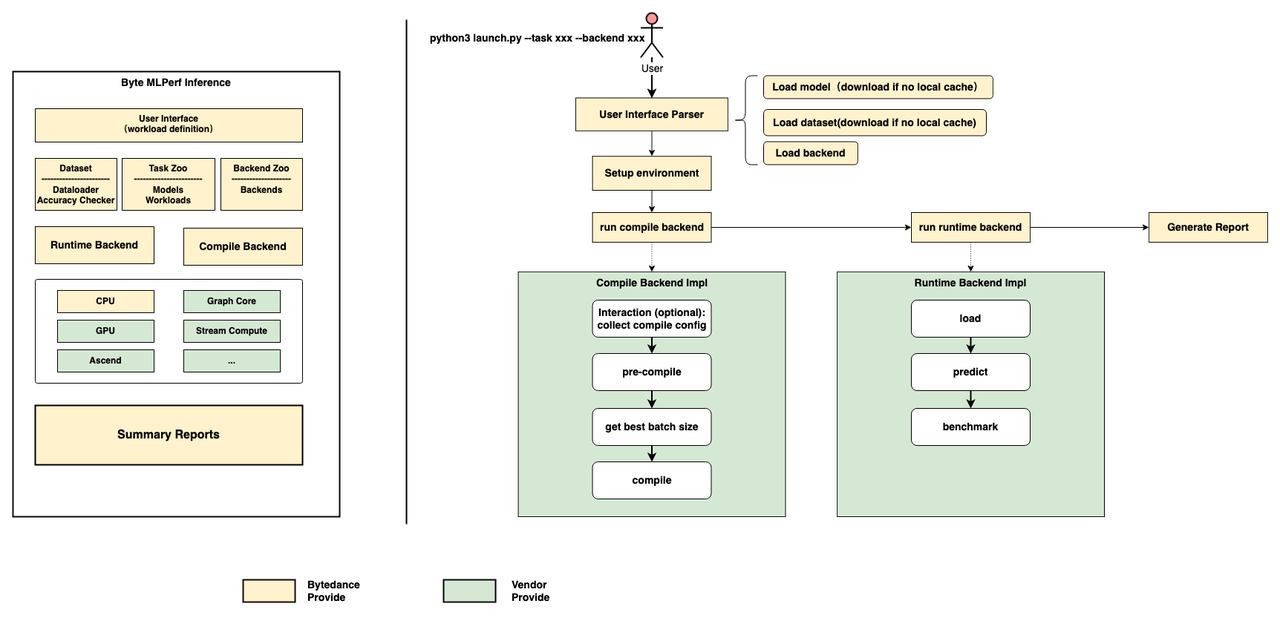
根据我们观察的业务实际使用场景,AI 业务生产流程抽象成了 ByteMLperf 的评估框架,可以先看看 ByteMLperf 的框架,主要包括 Task Zoo 和 Compile Backend 以及 Runtime Backend。
这么设计的原因是,一般一个 AI 生产业务中,模型上线部署的流程大概包括,训练,导出入库,优化压缩,上线部署;上线部署后,AI 服务又可以简单分为一个服务前端,模型前处理,模型运行,模型后处理等环节。
ByteMLperf 的设计是仿造模型导出入库、优化压缩、模型运行等环节设计的,其中 Task Zoo 可以类比成模型库,Compile Backend 可以理解成模型优化压缩工具,Runtime Backend 是类比模型运行。
而从右侧的评估流程也可以看出,ByteMLperf 对于模型的评估,是将实际部署环节的模型转换、性能压测简化出来。用这样的方法,可以保证评估的结果具备高可复现,迁移到实际业务中时也不会出现大的偏差。
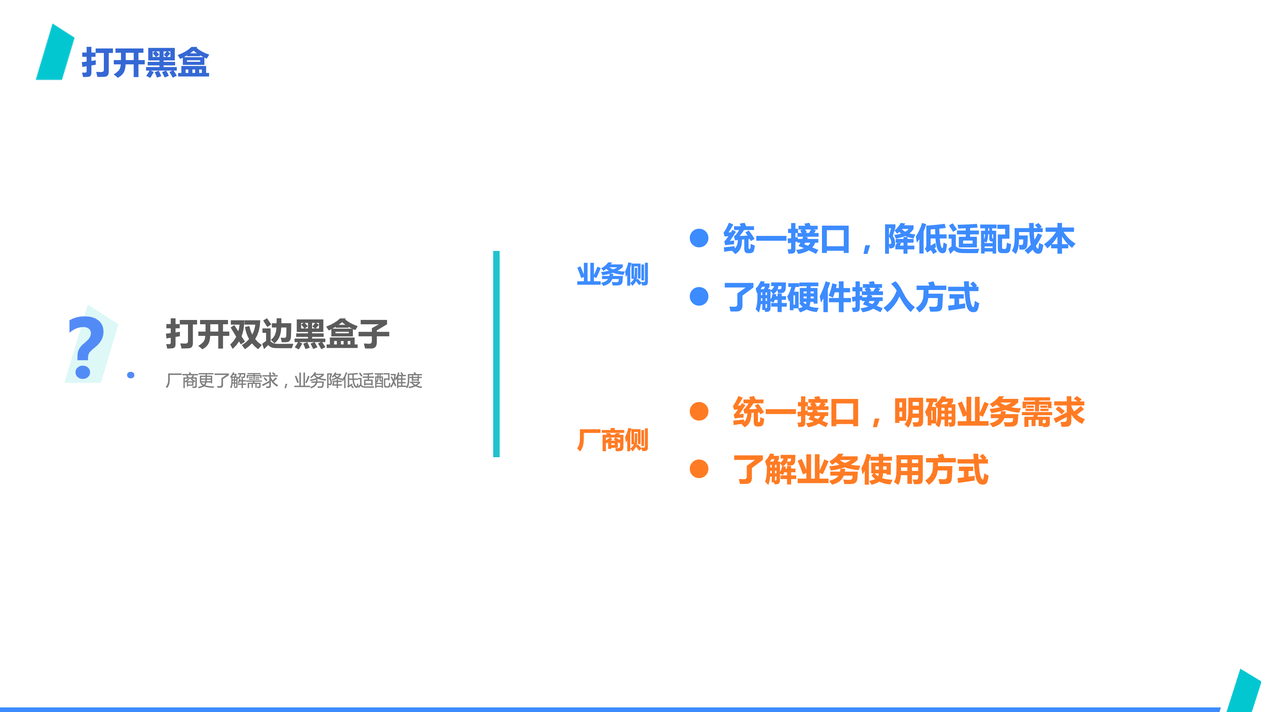
此外,由于约束了流程,也打开了两边的黑盒子。
业务侧,由于定了统一抽象接口,业务可以不必关心接口之下不同硬件产品的细节,从而降低了适配成本,也可以提前了解硬件实现接入的方式;
而厂商侧,也因为统一接口,明确了接入需求,可以提前适配,也更了解业务使用方式,降低了重复工作的可能。
ByteMLperf 也希望可以成为业务和厂商中间的桥梁,使得 ASIC 落地更丝滑一些。
以结果为导向
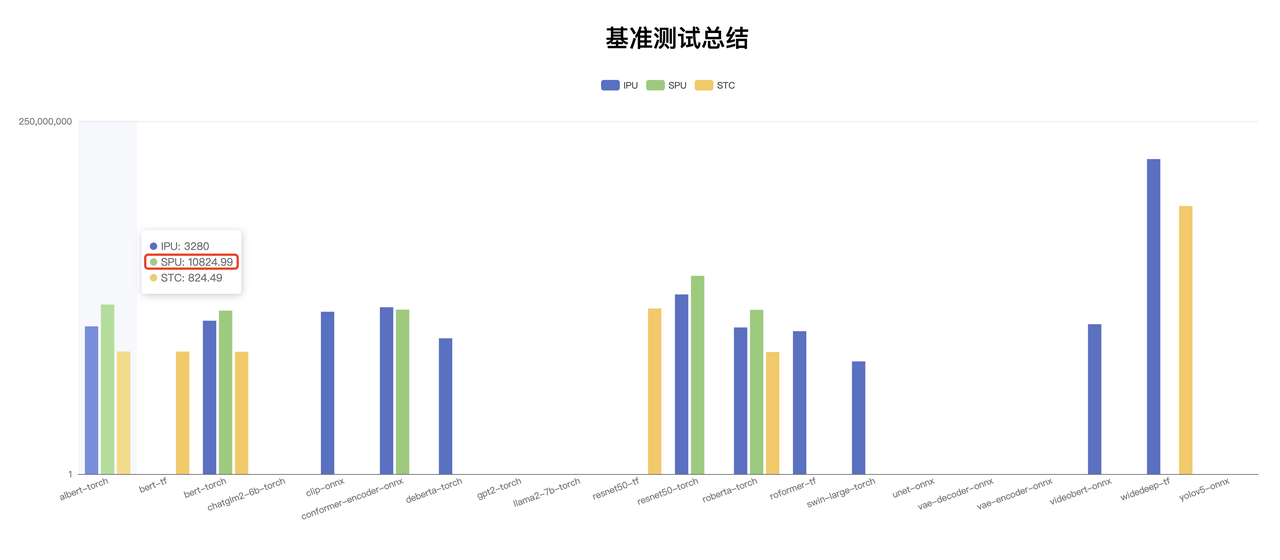
最后来看一个以结果为导向的例子。
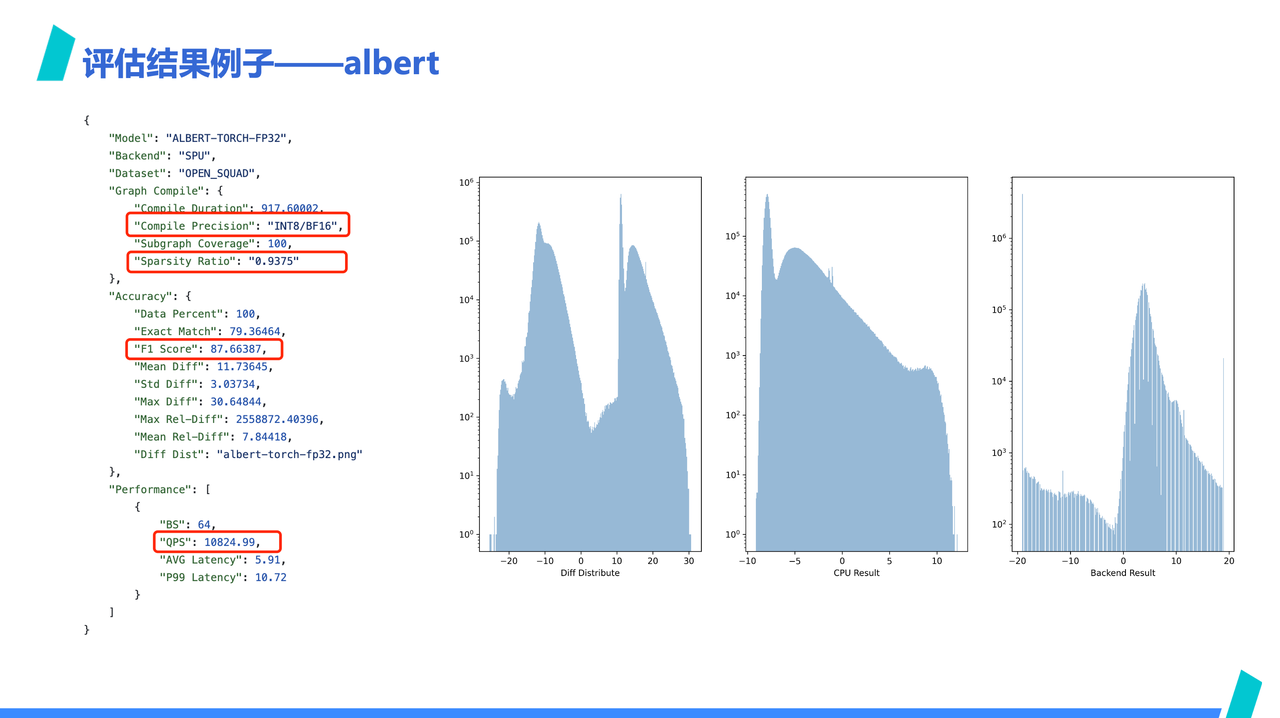
我们在性能大盘看到 SPU 在 albert 上高出很多,但算力上 SPU 并没有高出这么多,通过查看 SPU albert 的 report 细节,发现 SPU 是应用了 INT8/BF16 混合精度以及使用了 16 倍稀疏化,才达成了上一页中遥遥领先的 QPS 数据,这一点,从右侧的数值分布图也可以看出来,经过稀疏化后,SPU 的结果已经和 CPU 的结果基本无法对齐了
也许会有人好奇,混精度、稀疏化的结果为什么要和其他非稀疏化的放在一起比呢?原因是因为 ByteMLperf 是以结果为导向,对于黑科技持开放态度。具体到这个 case 来说,混合精度和稀疏化是否能被接受,不应该仅仅从别人没有使用混精度和稀疏化来否定,也即使用这类优化方法不是原罪,也许厂商在相应领域有黑科技呢?
相对的,这个结果是需要从给业务需求角度看待。例如,如果最终业务是看分类精度满足需求,而不是数值偏差多大,那 SPU 的稀疏加速就值得考虑,如果最终业务更关心数值漂移,那 SPU 就早早被排除在外。
此外,将所有硬件放一起横向比较,是因为 ROI 为导向的背景下,硬件性能会以各自价格归一化,只要能满足生产需要,芯片规格并非越高越好,而是要横向比较选择合适的。
总结
为了解决 ASICs 适配难,使用难的问题,ByteMLPerf 要做的不仅仅是一个基准评估。我们以面向 AI 生产场景为评估视角,以实际业务使用方式做评估,评估结果在生产场景可以直接复现,这个过程中,ByteMLPerf 也不仅充当一个评估套件,而是可以当做模型转换的生产工具使用。
同时,我们也在和使用者和供应商一起,将 ASIC 的使用经验、优化方法沉淀下来,形成知识,也希望围绕 ASIC 的使用建立一个社区,整合 AI 专用加速器的评估、优化和生态系统协作,促进 AI 专用加速器更好的服务于实际生产。
项目地址
-
Website: https://bytemlperf.ai/