Integration of Benchmark Testing, Optimization, and Ecosystem Collaboration for AI ASICs
Date: 2023-12-02
From September 26-28, the KubeCon + CloudNativeCon + Open Source Summit China 2023, hosted by the Linux Foundation and CNCF, was held in Shanghai. As active contributors and end-users in the community, the ByteDance and Volcano Engine teams made 7 presentations at the conference — KubeCon 2023 | How ByteDance Builds Cloud-Native Infrastructure for AI. This series of content is organized based on the conference presentations, and we welcome your attention.

ByteMlPerf, open-sourced by ByteDance, is a solution for "integrating evaluation, optimization, and ecosystem collaboration for AI ASICs."
This presentation is divided into three parts:
-
The first part introduces the background, namely what AI ASICs are and why they are increasingly gaining attention;
-
The second part explains the motivation behind ByteMlPerf, especially considering the high reputation of MLPerf in the industry;
-
The third part builds on the second and discusses how we address issues encountered when using ASICs.
Background
Why AI ASICs are Gaining Attention
Let's first review the development process of neural networks.
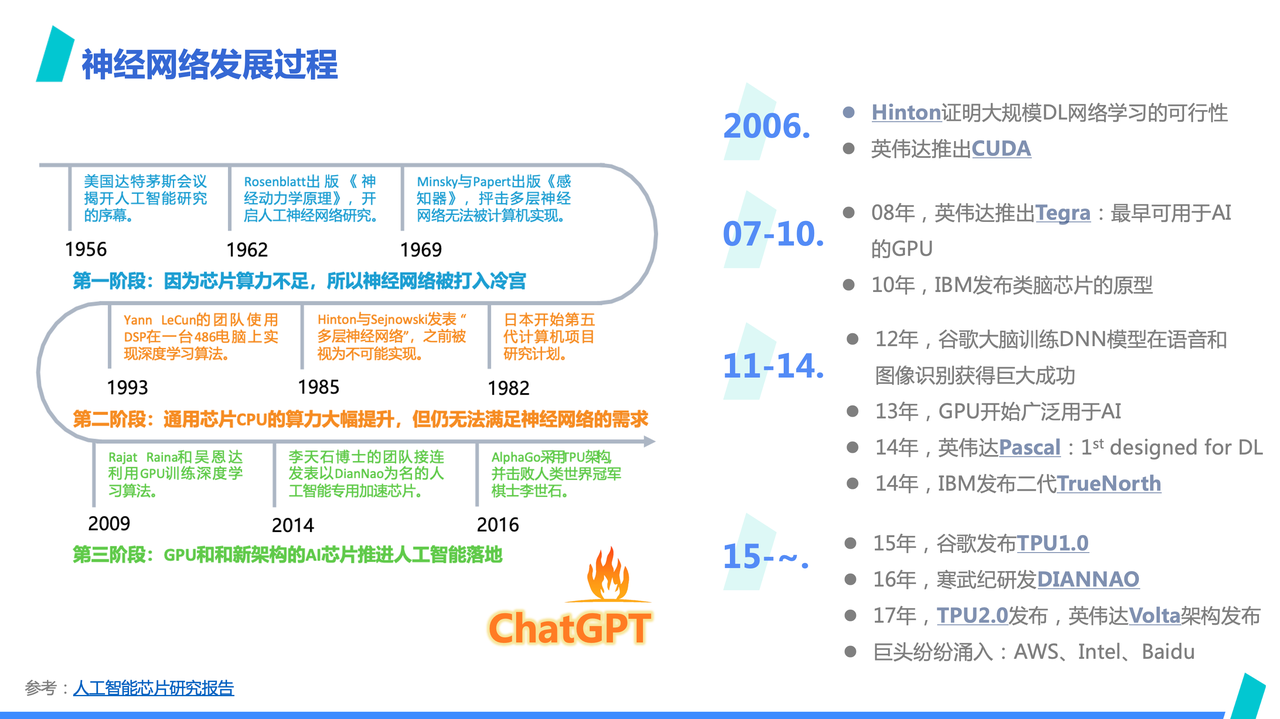
The image above, from an artificial intelligence chip research report, shows that neural networks have gone through three stages in history, each closely related to the increase in computing power:
-
The first stage saw neural networks falling out of favor due to insufficient CPU computing power;
-
In the second stage, despite some progress with improved CPU capabilities, the lack of computing power was still a major issue, leading to limited development;
-
The third stage witnessed the emergence of GPUs and other new architecture AI chips, providing sufficient computing power. Coupled with the accumulation of training data in the internet world, neural networks began to flourish.
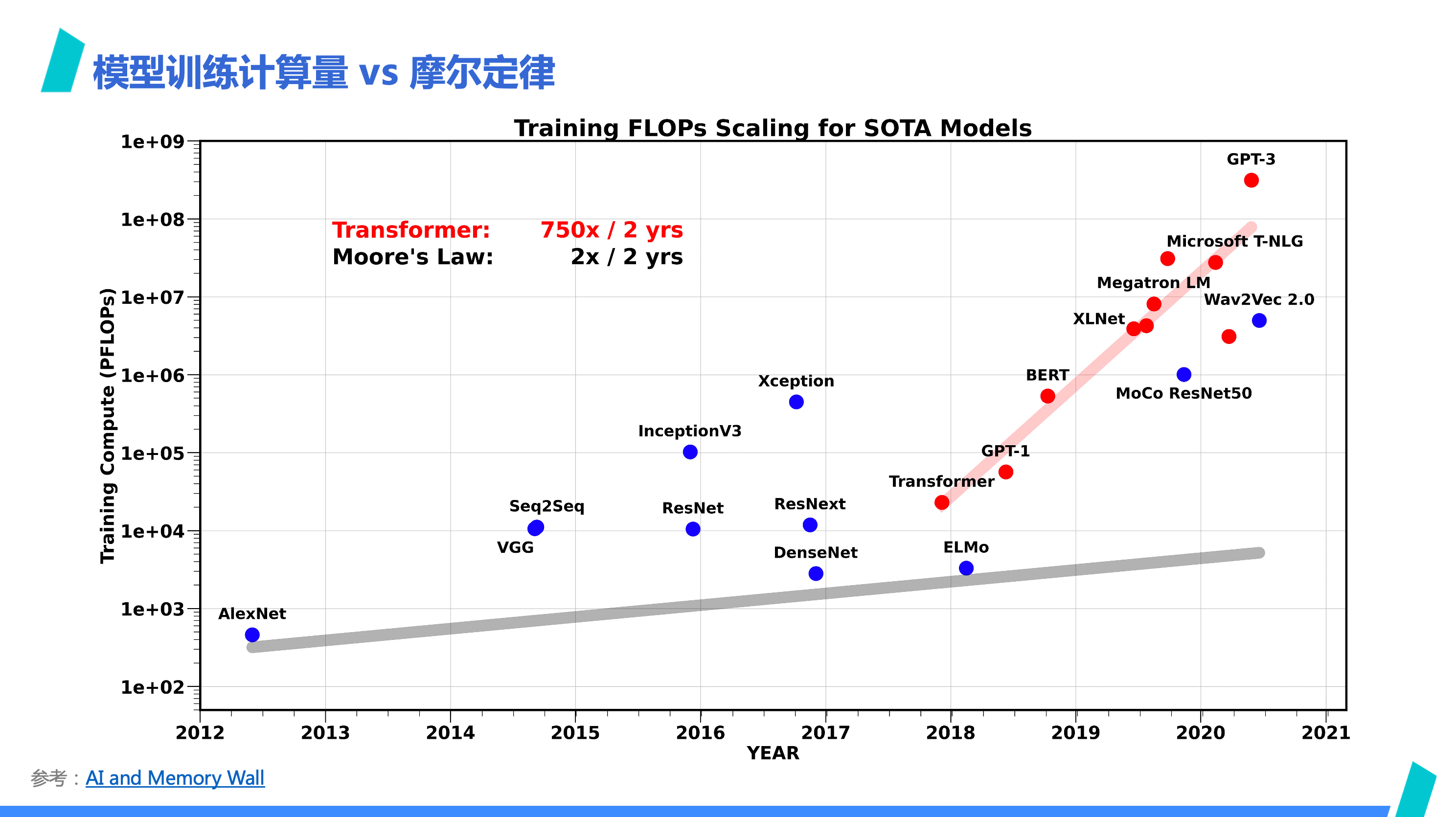
The comparison chart of "Model Training Computational Load and Moore's Law" from AI and Memory Wall shows that Moore's Law cannot keep up with the computing power required for training Transformer-type models. As Moore's Law reflects the development of chip manufacturing processes, the significant gap between the red and gray lines implies that relying on general-purpose computing chips with more transistors to increase computing power can hardly meet the demand. Hence, cluster computing becomes more essential.
This answers the first question of why AI ASICs are gaining attention — under physical world constraints, general-purpose computing power based on Moore's Law cannot meet growing demands. To break through, specialized computing architectures become one of the few viable paths.
What are AI Dedicated Acceleration Chips
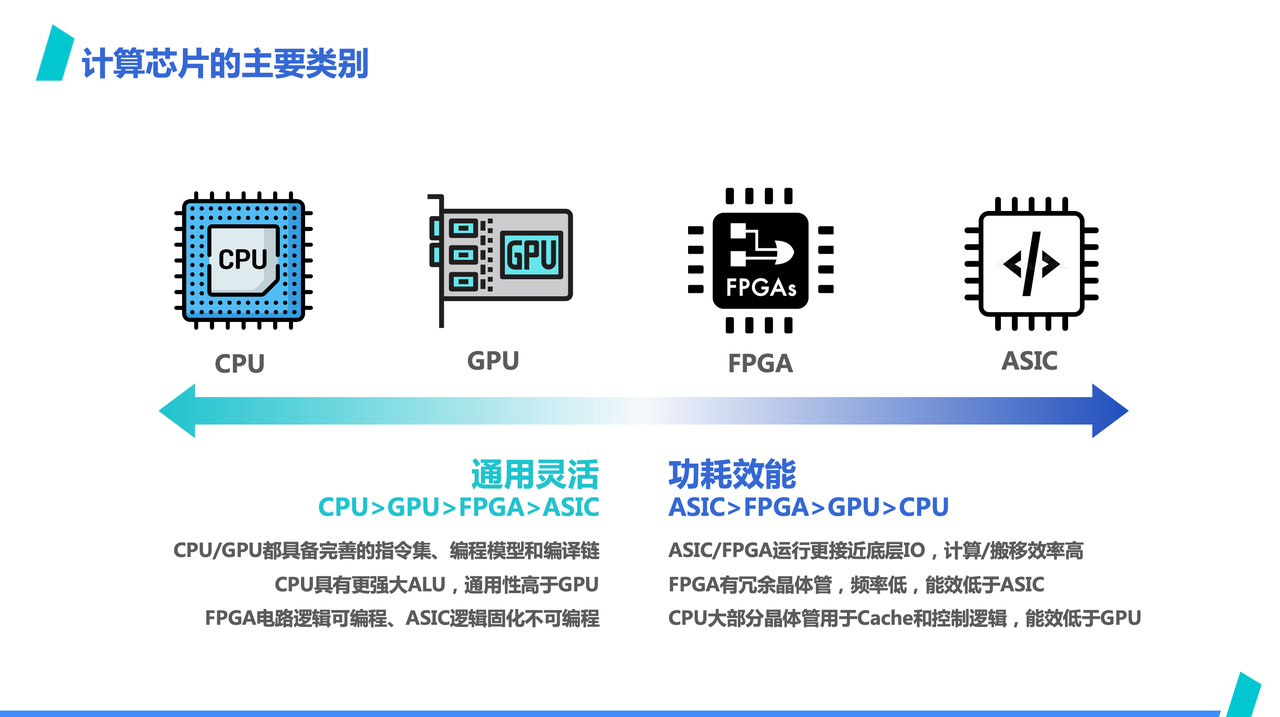
AI dedicated acceleration chips are defined in contrast to general-purpose computing chips. As mentioned, CPUs and GPUs are considered general-purpose computing power, capable of running a diverse range of computational workloads. CPUs are self-explanatory, and GPUs, besides AI, can also run image processing and high-performance computing loads. AI dedicated acceleration chips, however, are generally only capable of running AI workloads.
When talking about AI dedicated acceleration chips, we often refer to the two categories on the right side. However, since FPGAs are often used more for design validation and are rarely seen in mass-produced products, when mentioning AI dedicated acceleration chips, we are primarily talking about AI ASICs. Strictly speaking, some AI NPU architectures that offer certain flexibility may not strictly belong to ASICs, but for simplicity, they are temporarily classified under ASICs here, using ASICs to represent AI dedicated acceleration chips.
This shows that ASICs are most outstanding in terms of energy efficiency compared to general-purpose chips. This is because their underlying operational logic is closer to IO, lacking the complex circuit logic of general-purpose chips. With the same chip area, ASICs can reserve more space for computing power, making it easier to produce higher-powered products. Correspondingly, AI ASICs, limited by architecture, are not as versatile as CPUs and GPUs and are generally only capable of running AI workloads. They lack flexibility in programming.
Let's look at an example — the Habana Goya architecture. This is an AI inference card by Habana Lab, a typical ASIC architecture, very simple and AI-specific.
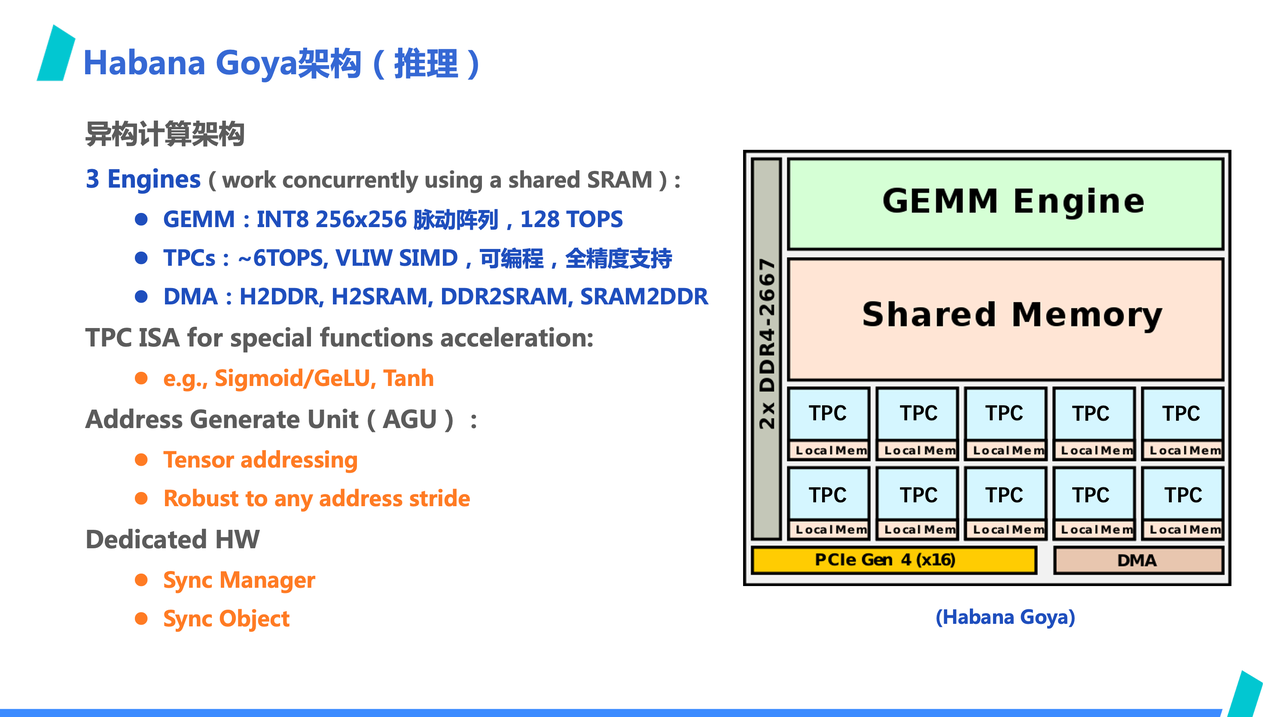
Firstly, the architectural diagram on the right shows no complex control logic like addressing and decoding. Data transfer is through shared SRAM, and synchronization is managed by a dedicated Sync Manager hardware, similar to a hardware semaphore. The computing power mainly comprises a GEMM Engine and 8 TPCs, with GEMM providing the primary multiplication and addition computing power. TPCs serve as a supplement for non-multiplication and addition computations, mainly because the primary operation in current AI workloads is multiplication and addition.
To better fit AI computing, the address generation unit, along with dedicated DMA, can achieve Tensor-style memory access, converting Tensor indices into corresponding linear addresses and supporting corresponding dimensional boundary checks. Apart from the -1 axis, other dimensions support arbitrary stride memory access. Additionally, the instruction sequences of GEMM, TPC, and DMA are independent, and the pipeline operation hides latency.
Moreover, TPCs also include common activation functions in AI workloads as special instructions, like sigmoid and gelu.
Why Create ByteMLPerf
Before answering this question, we need to address why AI ASICs are not commonly seen in business production.

According to our experience, although AI ASICs can solve computing power supply issues, using them to provide computing power is not easy for a company.
Firstly, product choice is difficult. How to choose the right product is a problem in itself. This might be hard to understand for companies using GPU products, but facing the myriad of AI acceleration chips on the market, choosing the right one for business is a challenge.
Secondly, there's high unpredictability. Unlike GPUs, AI ASICs, as new products, have higher unpredictability in whether they can ultimately be applied to business.
Thirdly, high adaptation cost. ASICs generally lack a mature developer ecosystem, making them difficult to use.
Fourthly, high opacity. Due to the inflexibility and weak programmability of ASICs, they rely heavily on their compilers, which are usually invisible to users.
Where is the Difficulty in Product Choice

Let's take a look at a chart, a panorama of AI chips organized by Dr. Tang Shan. The chart is from 2019 and is somewhat outdated today. But it still shows some issues — facing so many diverse products from various startups, which one to choose?
The answer is not just about choosing the strongest chip on paper but also considering company personnel stability, financing ability, delivery capability, customer support capacity, and software and hardware iteration cycles. After all, the lifecycle of hardware products is relatively long and requires long-term investment.
Where is the Unpredictability
Firstly, the cycle of introducing hardware products is long, often requiring cross-departmental communication and collaboration, involving business, systems, and supply. After selecting a new product based on hardware specifications, whether it can meet expectations in actual business applications is risky. If the actual business effect does not reflect the designed specifications, the costs invested in early adaptation and testing become sunk costs.
Unpredictability is not only in throughput and latency but also in accuracy. When migrating from GPU to ASIC, although the algebraic calculations are equivalent, model output numerical drift generally occurs, and whether this drift is acceptable in business scenarios is also a risk.
Where is the High Adaptation Cost
One situation that may arise with ASICs is that a product from a particular company may perform well in one business direction but average in another.
To meet different business load characteristics, it might be necessary to introduce multiple ASICs from different companies. Since each ASIC lacks a development ecosystem like CUDA, they often require separate adaptation. Each ASIC typically comes with its own software stack, requiring additional development in usage, hardware management, and monitoring integration.
Compared to continuing with GPUs, these are additional costs.
Where is the Opacity
Regarding opacity, as mentioned in the Habana example, ASIC architectures might seem simple at first glance, but many hardware design details are core technologies and inaccessible to end-users.
In terms of software, ASIC companies generally provide a complete software stack for their products, including compilers, which are also opaque to end-users.
Most ASICs make it difficult for developers to optimize AI model performance on ASICs like they would with CUDA Kernels, often allowing only limited optimization.
ByteMLPerf Solution
Comparison and Differences
In the second part, one point was not mentioned — with MLPerf already existing, why create ByteMlPerf? Simply put, MLPerf is difficult to meet actual business evaluation needs. Here's a simple comparison:
Firstly, the evaluation perspectives differ. ByteMlPerf is initiated purely from the user's perspective, while MLPerf is hosted by a supplier committee, leading to different focuses.
Secondly, in terms of fairness, ByteMlperf does not require apple-to-apple alignment but is result-oriented, accepting manufacturers' proprietary technologies.
Then, ByteMlPerf's evaluation set updates faster, closely following business needs and SOTA models. When we notice that widely used models in business are evolving, we will update them promptly and notify manufacturers.
Lastly, ByteMLPerf will restrict the way of evaluation access according to business usage, abstracting the usage method into an API, defining the API return format, but not the implementation process of the API.
As a result, MLPerf's evaluation outcomes become a place for manufacturers to flex their muscles, but the numbers in the evaluation results are far from actual business applications.
Features of ByteML

Firstly, transparency and reproducibility. Open source goes without saying, but transparency is demanded because we require manufacturers not only to provide evaluation results but also to offer a reproducible environment. This includes how to achieve the evaluation results under the ByteMLPerf framework. This ensures the reproducibility of the evaluation results as much as possible, and similar results can be obtained when similar models are used in actual business scenarios.
Secondly, tailored for AI production scenarios. This means that ByteMLPerf's evaluation process is designed based on actual production scenarios. To some extent, ByteMLPerf is not just an evaluation suite; it can actually be used as a production tool and integrated into the production process.
Thirdly, keeping pace with business needs and state-of-the-art (SOTA) technology. To ensure consistency with the latest technologies and business requirements, ByteMLPerf continually updates its benchmark tests to reflect current business scenario needs and cutting-edge technology, providing users with the latest and most relevant performance evaluations. This also allows manufacturers to stay informed about which models are widely used.

To address the issue of difficult choices, ByteMLPerf has collected information on commonly available hardware products in the market and summarized them, as seen in this image. Of course, the overview does not include all products available in the market, as ByteMLPerf filters out some immature hardware and software products through its evaluation access constraints and report submission thresholds.
Of course, being temporarily absent from the overview does not mean that a product is immature. Instead, it reflects the time needed for contacting manufacturers, gathering information, integrating evaluations, and submitting reports. We need more time to collect further information.
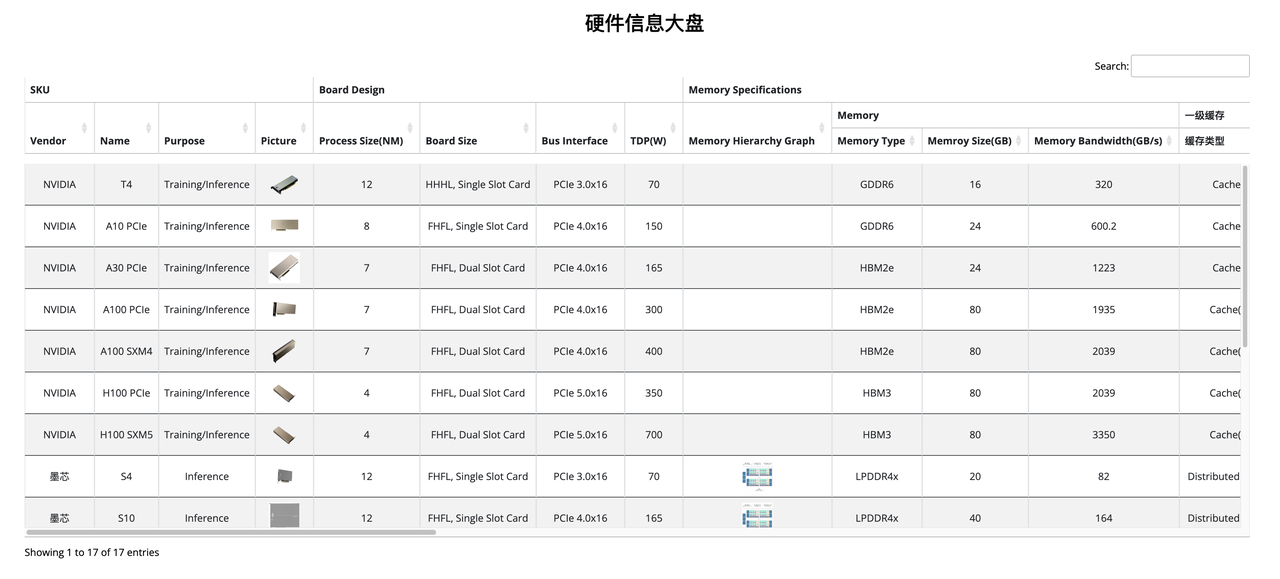
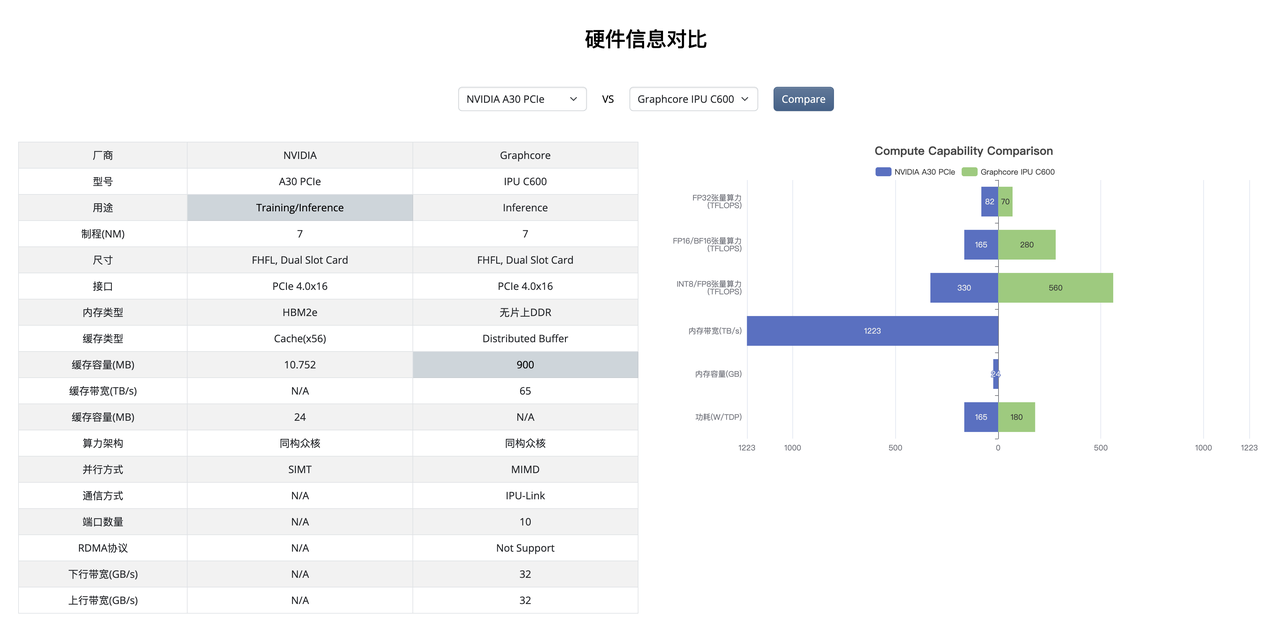
In order to solve the problem of difficult choices, we designed a hardware information comparison feature. If you're unsure how to choose in the first step, you can start by comparing with the products you're currently using, to see which products are similar or superior in specifications. In the second step, you can check whether the manufacturer has submitted reports for models heavily used in your current business. If so, the next step would naturally be to further contact the manufacturer.
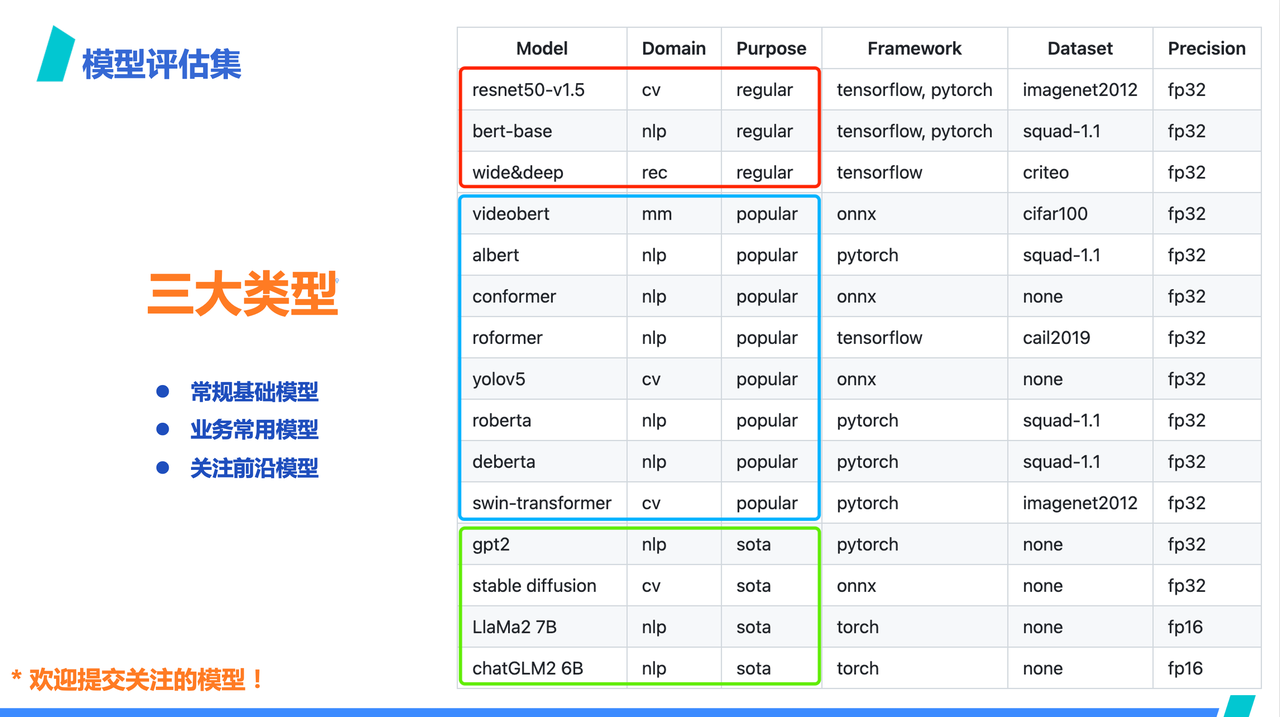
We hope to reduce the risk of unpredictability through comprehensive evaluation sets. As mentioned earlier, to ensure alignment with the latest technologies and business requirements, ByteMLPerf continuously updates its benchmark tests. This can be simply divided into three parts:
-
Regular Benchmark Models. In the reporting standards of ByteMLPerf, manufacturers are required to submit reports for at least 5 different models, including regular models which are mandatory. If these regular models are not well supported, they do not meet the entry requirements of ByteMLPerf.
-
Business Common Models. These are models commonly used in businesses, filtered based on actual business usage. In this selection, manufacturers can choose to focus on particular areas, such as language processing or image processing.
-
SOTA Models. This considers the long-term investment in hardware products. Models not widely used now may soon be extensively utilized in production scenarios.
We welcome everyone to submit models of interest to ByteMLPerf!
According to the business scenarios we observed, the AI business production process is abstracted into ByteMLPerf's evaluation framework. Let's take a look at ByteMLPerf's framework, which mainly includes Task Zoo, Compile Backend, and Runtime Backend.
The reason for this design is that, in a typical AI production business, the process of model deployment involves training, exporting to a database, optimization, compression, and online deployment. After deployment, AI services can be divided into a service front end, model pre-processing, model operation, and post-processing.
ByteMLPerf's design imitates the stages of model export to database, optimization, compression, and model operation. Here, the Task Zoo can be compared to a model library, Compile Backend can be understood as a model optimization and compression tool, and Runtime Backend is analogous to model operation.
From the evaluation process on the right side, you can see that ByteMLPerf's model evaluation simplifies the actual deployment stages of model conversion and performance stress testing. This method ensures high reproducibility of evaluation results, and when migrated to actual business scenarios, there won't be significant deviations.
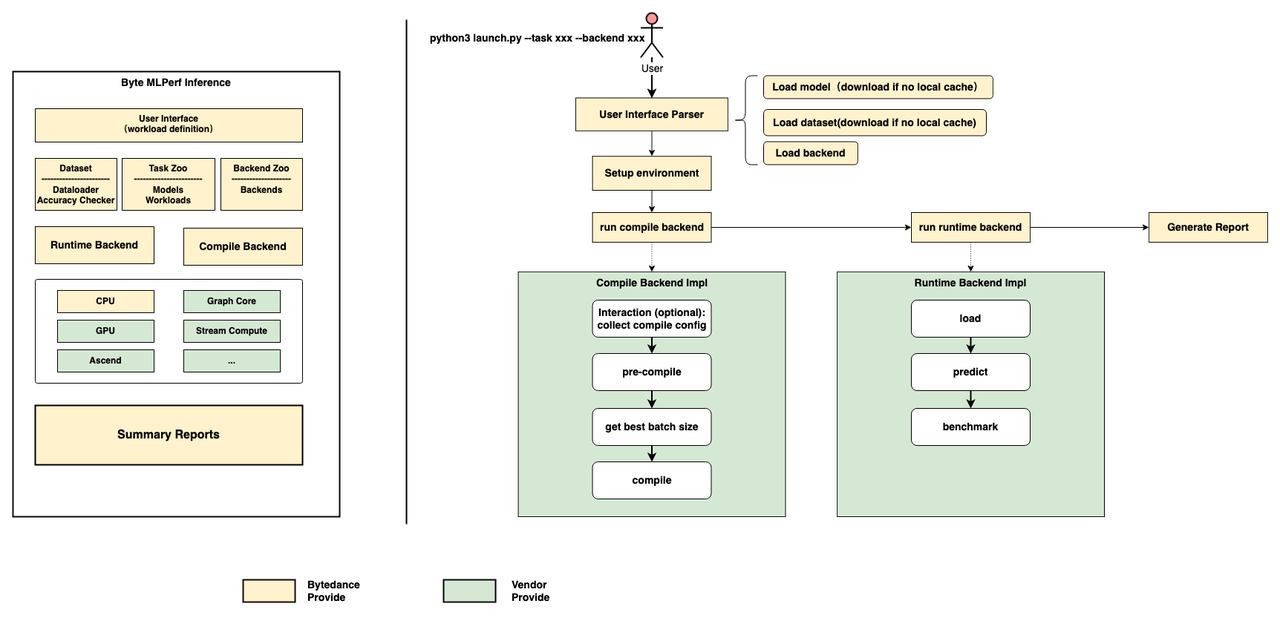
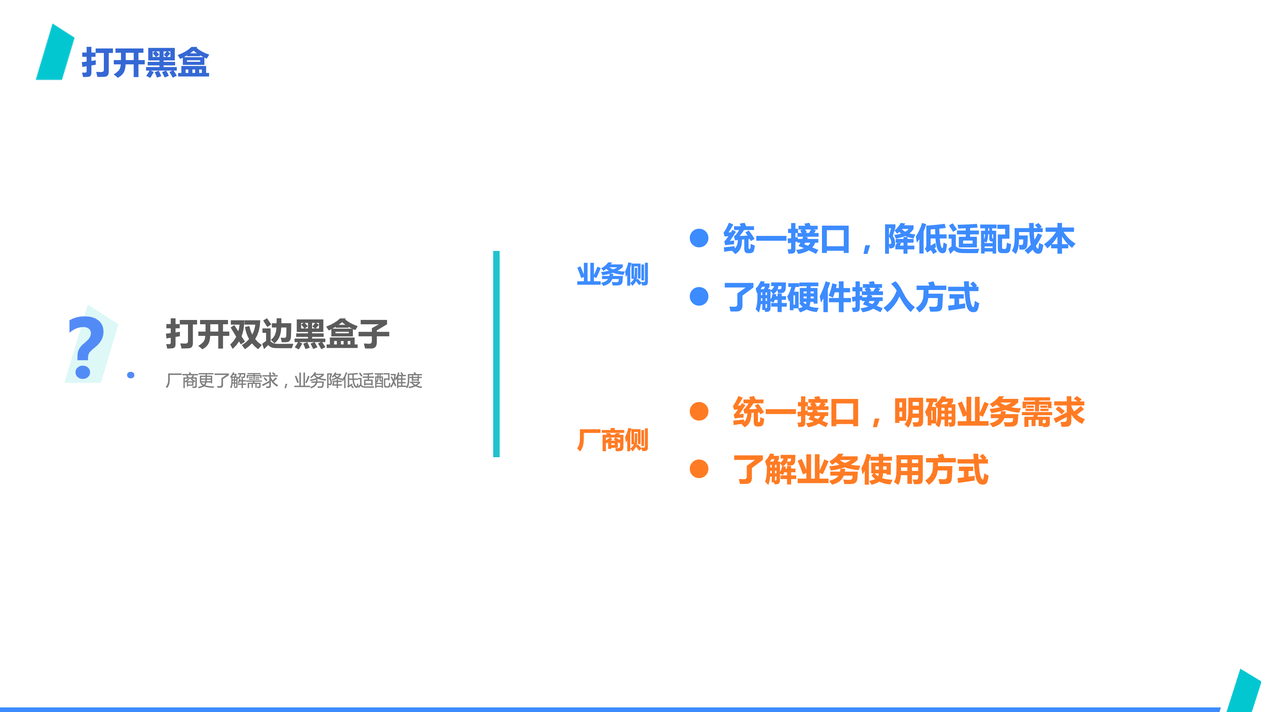
Additionally, by constraining the process, it opens the black boxes on both sides.
On the business side, due to the unified abstract interface, businesses do not need to worry about the details of different hardware products below the interface, thus reducing adaptation costs and gaining an understanding of the hardware implementation access methods in advance.
On the manufacturer side, due to the unified interface, the access requirements are clear, allowing for early adaptation and a better understanding of business usage methods, reducing the likelihood of repetitive work.
ByteMLPerf also hopes to act as a bridge between businesses and manufacturers, making the implementation of ASICs smoother.
Result-Oriented Approach
Result-Oriented Approach
Finally, let's look at an example of a result-oriented approach.
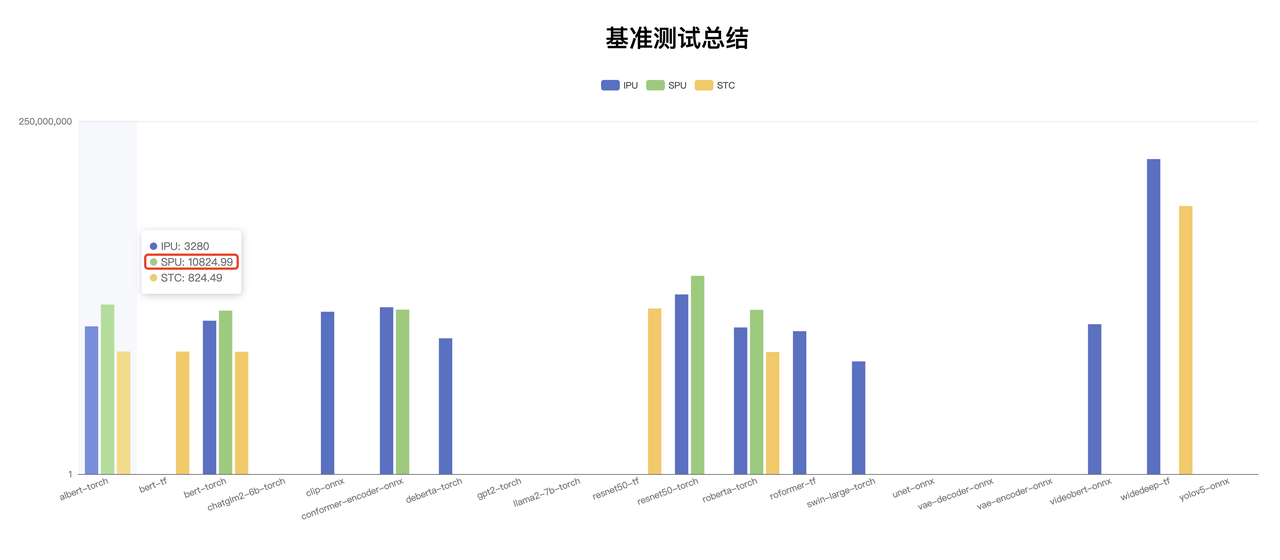
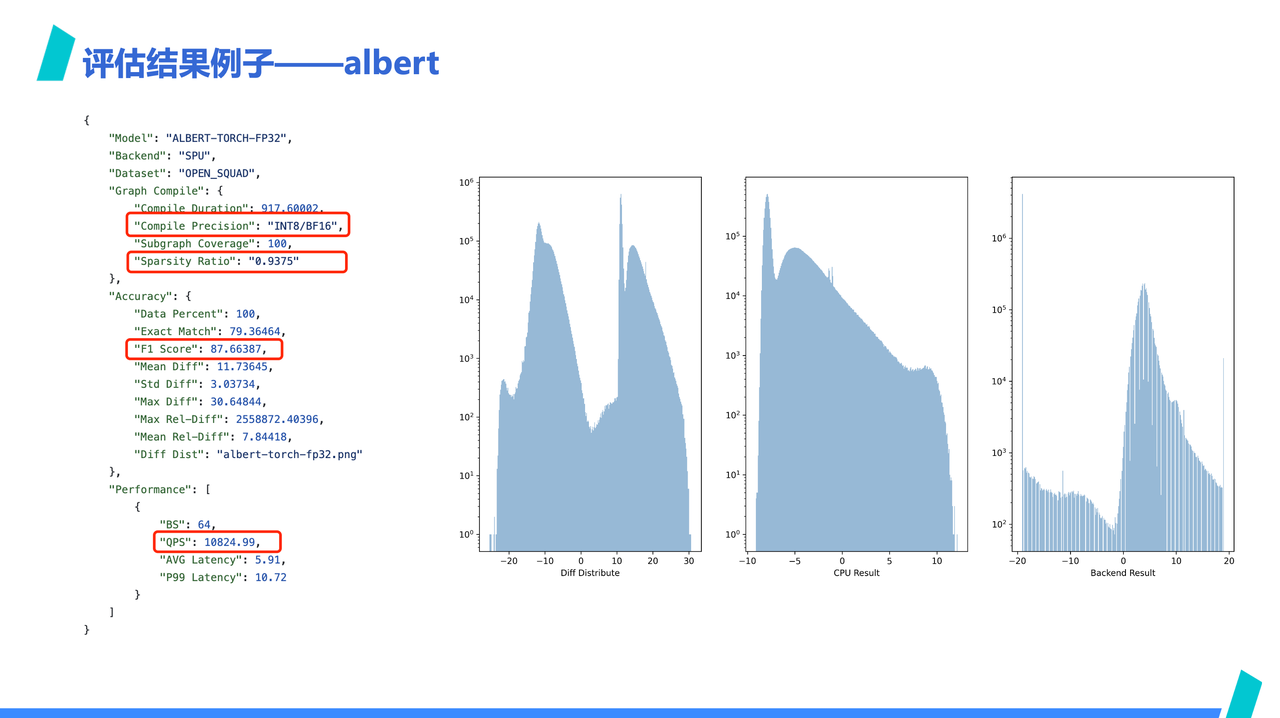
In the performance dashboard, we see that SPU is significantly higher than Albert, but in terms of computing power, SPU is not that much higher. By examining the details of SPU Albert's report, it's revealed that SPU applied INT8/BF16 mixed precision and 16x sparsification to achieve the leading QPS data on the previous page. This can be seen from the value distribution chart on the right, where after sparsification, SPU's results are almost unaligned with CPU's.
with non-sparsified ones? The reason is that ByteMLPerf is result-oriented and open to innovative technologies. Specifically for this case, whether mixed precision and sparsification are acceptable should not be denied simply because others haven't used them. In other words, using such optimization methods is not inherently wrong; perhaps the manufacturer has innovative technologies in the corresponding field.
On the other hand, the result needs to be viewed from the perspective of business requirements. For example, if the final business is concerned with classification accuracy meeting the needs, rather than how large the numerical deviation is, then SPU's sparsified acceleration is worth considering. If the final business is more concerned with numerical drift, then SPU would be excluded early on.
Additionally, comparing all hardware side by side is because, under the ROI-oriented background, hardware performance is normalized to their respective prices. As long as they meet production needs, chip specifications are not necessarily better when higher. Instead, appropriate choices should be made through horizontal comparison.
Summary
To address the difficulties in adapting and using ASICs, ByteMLPerf aims to do more than just benchmark evaluation. We evaluate from the perspective of AI production scenarios, with actual business usage methods for evaluation, ensuring that the evaluation results can be directly reproduced in production scenarios. In this process, ByteMLPerf not only acts as an evaluation suite but can also be used as a model conversion production tool.
At the same time, we are working with users and suppliers to accumulate experience and optimization methods for using ASICs, forming knowledge. We also hope to establish a community around the use of ASICs, integrating the evaluation, optimization, and ecosystem collaboration of AI-specific accelerators, to promote their better service in actual production.
Project Address
-
Website: https://bytemlperf.ai/