ByteMLPerf Inference General Perf Overview
Byte MLPerf is an AI Accelerator Benchmark that focuses on evaluating AI Accelerators from practical production perspective, including the ease of use and versatility of software and hardware.
- Models and runtime environments are more closely aligned with practical business use cases.
- For ASIC hardware evaluation, besides assessing performance and accuracy, it also examines indices like compiler usability and coverage.
- Performance and accuracy results obtained from testing on the open Model Zoo serve as reference metrics for evaluating ASIC hardware integration.
Architecture
The ByteMLPerf architecture is shown in the figure below:
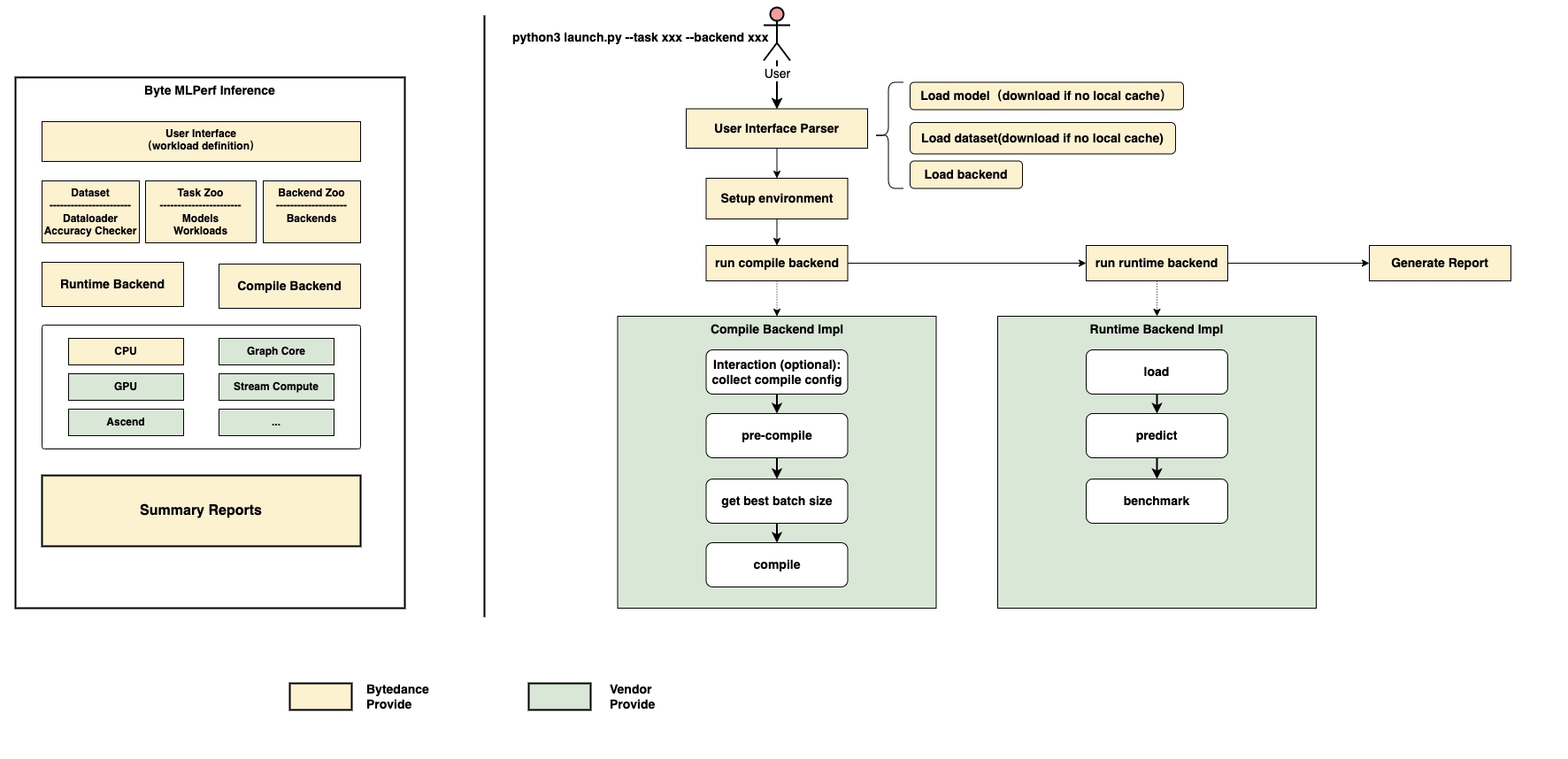
Model Zoo List
The models supported by ByteMLPerf Inference General Perf are collected under the Model Zoo. From the perspective of access rights, they are currently divided into internal models and open models. Released with ByteMLPerf is the open model included in the corresponding version.
Open model collection principles:
- Basic Model: including Resnet50, Bert and WnD;
- Popular Model:Includes models currently widely used in the industry;
- SOTA: including SOTA models corresponding to business domains;
In addition to the complete model structure, ByteMLPerf will also add some typical model substructure subgraphs or OPs (provided that the open model cannot find a suitable model containing such classic substructures), such as transformer encoder/decoder with different sequence lengths , all kinds of common conv ops, such as group conv, depwise-conv, point-wise conv, and rnn common structures, such as gru/lstm, etc.
| Model | Domain | Purpose | Framework | Dataset | Precision |
|---|---|---|---|---|---|
| resnet50-v1.5 | cv | regular | tensorflow, pytorch | imagenet2012 | fp32 |
| bert-base | nlp | regular | tensorflow, pytorch | squad-1.1 | fp32 |
| wide&deep | rec | regular | tensorflow | criteo | fp32 |
| videobert | mm | popular | onnx | cifar100 | fp32 |
| albert | nlp | popular | pytorch | squad-1.1 | fp32 |
| conformer | nlp | popular | onnx | none | fp32 |
| roformer | nlp | popular | tensorflow | cail2019 | fp32 |
| yolov5 | cv | popular | onnx | none | fp32 |
| roberta | nlp | popular | pytorch | squad-1.1 | fp32 |
| deberta | nlp | popular | pytorch | squad-1.1 | fp32 |
| swin-transformer | cv | popular | pytorch | imagenet2012 | fp32 |
| stable diffusion | cv | sota | onnx | none | fp32 |
Vendor List
ByteMLPerf Inference General Perf Vendor List will be shown below
| Vendor | SKU | Key Parameters | Supplement |
|---|---|---|---|
| Intel | Xeon | - | - |
| Stream Computing | STC P920 | STC Introduction | |
| Graphcore | Graphcore® C600 | IPU Introduction | |
| Moffett-AI | Moffett-AI S30 | SPU Introduction |
With ByteIR
The ByteIR Project is a ByteDance model compilation solution. ByteIR includes compiler, runtime, and frontends, and provides an end-to-end model compilation solution.
Although all ByteIR components (compiler/runtime/frontends) are together to provide an end-to-end solution, and all under the same umbrella of this repository, each component technically can perform independently.
For More Information, please refer to ByteIR
Models Supported By ByteIR:
| Model | Domain | Purpose | Framework | Dataset | Precision |
|---|---|---|---|---|---|
| resnet50-v1.5 | cv | regular | mhlo | imagenet2012 | fp32 |
| bert-base | nlp | regular | mhlo | squad-1.1 | fp32 |